弊家では銀行やクレジットカードの明細を BigQuery に取り込んでダッシュボードを作ったりしています。 また、そのために作った BigQuery 向けの Go 製 ETL フレームワークを OSS として公開しました。 本記事ではざっくりどんなもんかを紹介して、どう作るのかを説明します。
Google Cloud Platform Advent Calendar 2020 の 13 日目の記事です。
Google Cloud Japan の Customer Engineer の Advent Calendar もぜひご覧ください。
TL; DR
- 明細が BigQuery にあると、可視化もできるしアラートも出せるし、まぁなんでもできて便利
- 銀行明細レベルのデータならほぼ無料で保存、ETL、分析できる
- ETL フレームワーク bqloader を OSS として公開したから使ってくれよな 💪
説明しないこと:
- 我が家の台所事情
- BigQuery のクエリの書き方
対象読者
- GCP を触ったことがある人
- お金まわりを分析したいと思っている人
- 身近な題材で BigQuery を触ってみたい人
ざっくり紹介
何が嬉しいの?
BigQuery でできることができるようになります。 で終わらせるのもアレなので、弊家でのユースケースを列挙します。
- ダッシュボード
- 資産推移
- 出費分析
- でかい出費ランキング
- アラート (銀行残高、クレジットカード)
- 予算管理
例えばダッシュボードはこんな感じです。(記事用に加工してます)
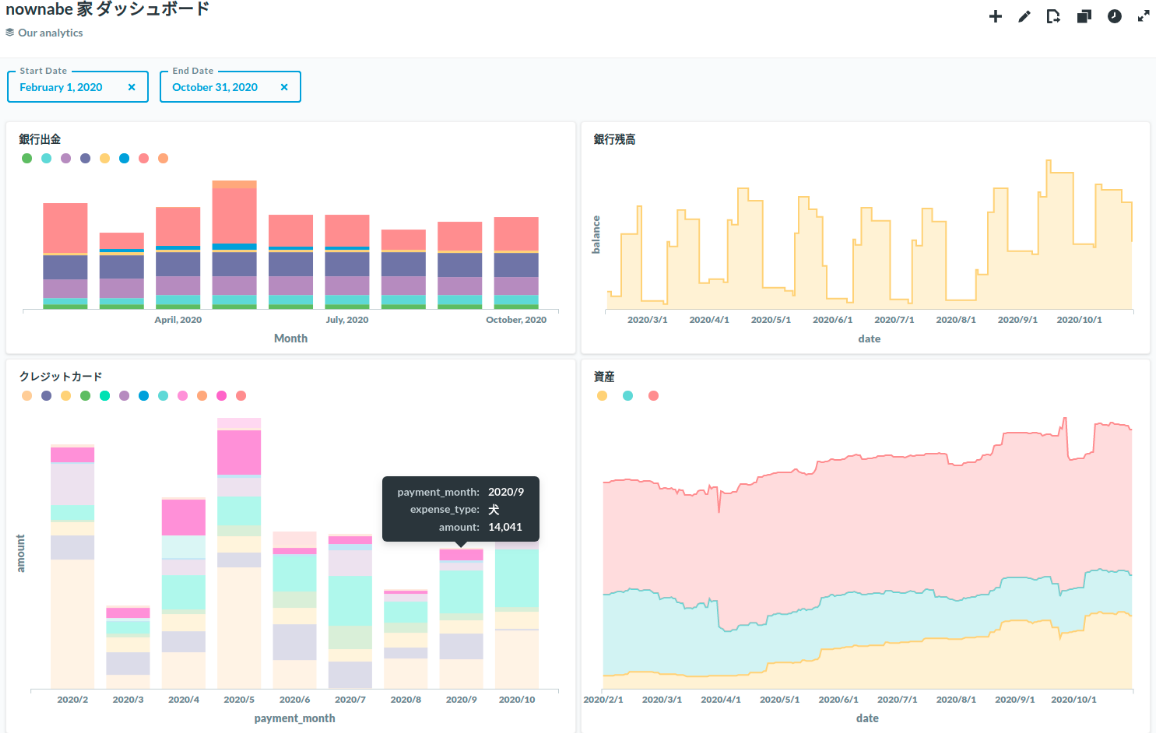
BigQuery を使うことで、手動でやってたことを自動化できるようになったり、今までできなかったことができるようになったりしました。 SQL を書けばほしいデータをほしい形ですぐに手に入れることができて、それを簡単に様々なシステムと連携できるので超便利です。 おかげで自動化もできたし、良い感じのダッシュボードも作ることができて節約を頑張れそうです。
Money Forward でええんちゃうの?
いいです 😂
本記事の内容は劣化版 Money Forward の再実装と言える部分もあります。
Money Forward はとてもいいサービスなので弊家でも使っていますが、かゆいところに手が届かなかったり、使いたい機能が有料だったりしたので自分でも作りました。
自分で作ると手間はかかりますが Money Forward 以上のやりたいことがだいたい実現できるようになります。 BigQuery でクエリを書いて好きな結果を得られるというのは大きいですね。
アーキテクチャ
こんな感じです。
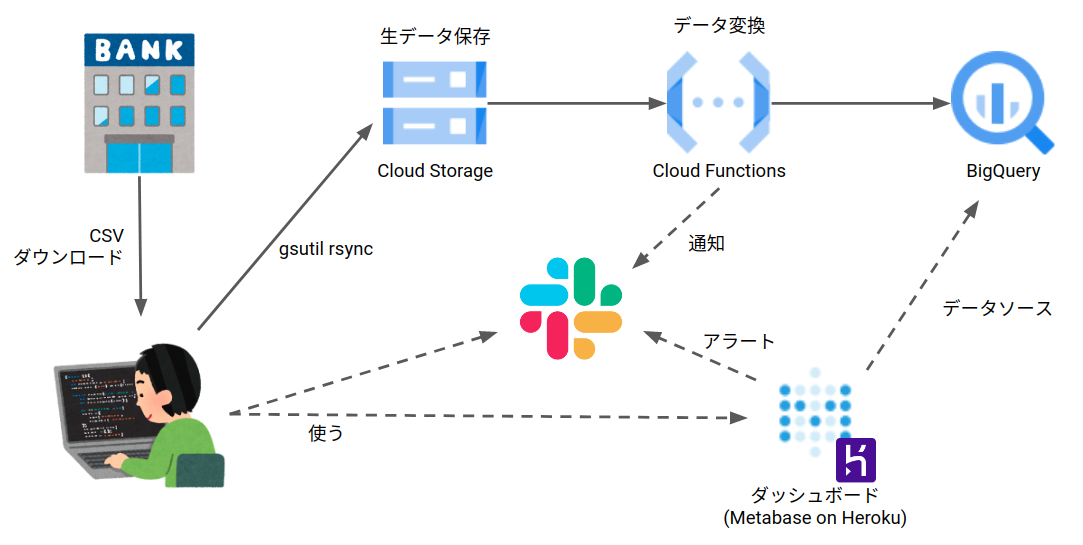
課題
大きな課題が 2 点あります。
- CSV のダウンロード/アップロードが手動
- 銀行やクレジットカードの明細の CSV を手動でダウンロードしてアップロードしています1
- リアルタイム性がない
- CSV を月イチで手動アップロードしてるので、リアルタイム性がありません
以前はスプレッドシートに手入力していた部分もあったので自分としては手間は減ってるし、できることは増えたし、お金はかかっていないしでハッピーなんですがめんどくささは残ります。 銀行が API 公開してくれたらいいんですけどね。
無料なの?
無料ではないです。毎月 1 円請求が発生しています。 Cloud Functions のコンテナイメージを管理している Container Registry のバックエンドの Cloud Storage に料金がかかっています。2
下の画像は実際に弊家で使っているプロジェクトの Billing Report です。 (Subtotal は 4 ヶ月分が加算されて 4 円と表示されています)
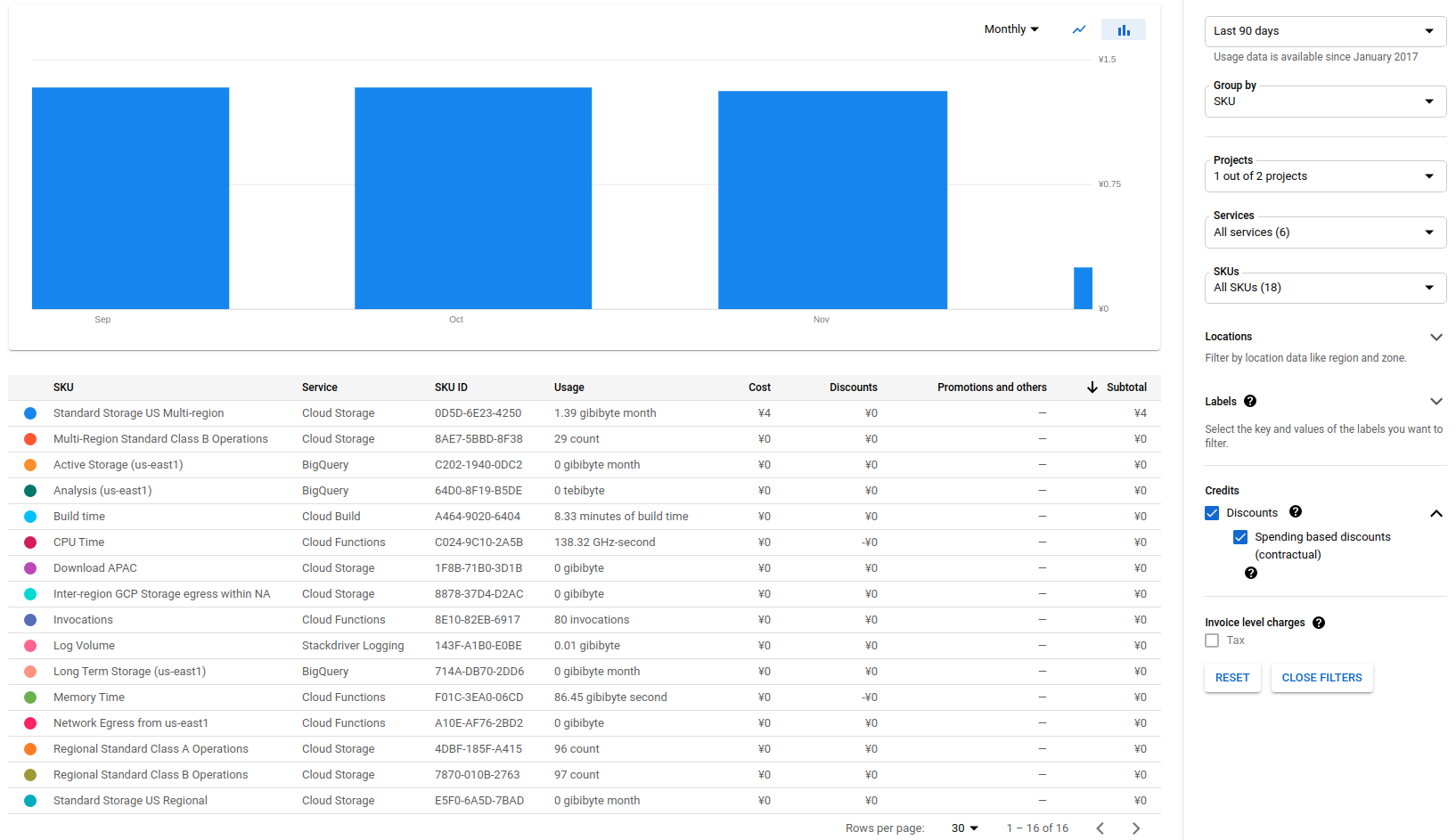
Cloud Storage や Cloud Functions や BigQuery は無料枠におさまっています。 もし既に無料枠を使い切っている場合は料金が発生します。それぞれ以下のように無料枠があります。
- Cloud Storage: 5GB-月 (us-east1, us-west1, us-central1)
- Cloud Functions: 200 万回/月
- BigQuery: 1TB クエリ/月
Cloud Storage の無料枠はリージョンが限定されています。
リージョンが異なると余計なネットワーク料金が発生したりするのでリージョンを揃えておくのもポイントです。
弊家ではすべてを使えるリージョンとして us-east1 を選択しました。
銀行の明細は 1 ヶ月分でせいぜい数 KB、クエリもたかがしれてるのでなかなか無料枠を超えることはなさそうです。
ETL フレームワーク bqloader
bqloader 概要
bqloaderは Go 製のシンプルな ETL フレームワークです。 弊家の ETL をフレームワークとして切り出したものになります。 以下のような特徴があります。
- 1 行を 1 行への変換に特化
- ユーザは行単位の変換ロジックのみ実装
- 簡単な設定で文字コード変換、不要な行のスキップ、成功・失敗通知が可能
- 今のところ Cloud Storage、Cloud Functions、BigQuery 専用3
- 1 つの Function で複数種のデータに対応
Go で実装することになるので Go の知識はあった方がいいですが、なくても Hello, world ぐらいできればサンプル見ながら実装できるんじゃないでしょうか。
以下のような利点があります。
- ほぼ無料で使える
- 必要最低限の機能しかない
- Go で書ける
- 複数種のデータの ETL を一箇所で管理できる
bqloader 使い方
サンプルプロジェクトを見てもらうのがはやいです。 このサンプルの中で Service Account の作成や Function のデプロイ、BigQuery への ETL まで一通りカバーしています。
以下ではフレームワークのさわりだけ丁寧に説明していきます。 詳しくはgodocやサンプルを見てください。
まず import します。
import "go.nownabe.dev/bqloader"
保存先テーブルごとに bqloader.Handler を設定します。
Cloud Storage にアップロードされたファイルが Handler の Pattern に一致する場合に処理されてテーブルにロードされます。
Handler を複数定義すればひとつの Pattern に複数の Handler を対応させることもできます。
handler := &bqloader.Handler{
Name: "main_bank", // 通知などで使われる
Encoding: japanese.ShiftJIS, // 入力ファイルをShiftJISとして扱う
Parser: bqloader.CSVParser(), // 入力ファイルをCSVとして扱う
// 先頭から1行を無視する (ヘッダのスキップ)
SkipLeadingRows: 1,
// この正規表現にマッチするパスのファイルを処理する
Pattern: regexp.MustCompile("^main_bank/"),
// ロード先のBigQueryテーブル
Project: "my-project",
Dataset: "my_dateset",
Table: "main_bank",
// 後述
Notifier: notifier,
Projector: projector,
}
変換のコアはprojectorです。projectorは行単位の変換を実現する関数です。
/*
例えば次のようなCSVの各行をBigQueryが理解できる形式に変換する。
日付,内容,出金金額,入金金額,残高
2020年12月13日,お賃金,0,"180,000","200,000"
rowに1行が入る。上記の例だと次のようになる。
row == []string{"2020年12月13日", "お賃金", "0", "180,000", "200,000"}
*/
projector := func(_ context.Context, row []string) ([]string, error) {
// 日本語の日付から、BigQueryが解釈できる日付に変換する
t, err := time.Parse("2006年01月02日", row[0])
if err != nil {
return nil, fmt.Errorf("time parse error: %v", err)
}
row[0] = t.Format("2006-01-02")
// 数値列のカンマを削除する
row[2] = strings.ReplaceAll(row[2], ",", "")
row[3] = strings.ReplaceAll(row[3], ",", "")
row[4] = strings.ReplaceAll(row[4], ",", "")
return row, nil
}
notifierは通知です。
notifier := &bqloader.SlackNotifier{
Token: "xxxx",
Channel: "#bqloader",
}
この Handler を利用して Cloud Functions のエントリーポイントとなる関数を実装します。3
func MyFunc(ctx context.Context, e bqloader.Event) error {
loader, _ := bqloader.New()
// 上述のmain_bank Handler
loader.MustAddHandler(ctx, handler)
// 別のHandlerも登録できる
loader.MustAddHandler(ctx, creditCardHandler)
// イベントを処理する
return loader.Handle(ctx, e)
}
Cloud Storage へのファイルアップロードなどのイベントで実行されます。4
こんな感じで bqloader による関数を Cloud Functions にデプロイして、対応するバケットにファイルをアップロードすればデータが BigQuery にロードされます。
BigQuery による台所事情分析の始め方
では銀行の明細を BigQuery にロードする ETL システムを構築してダッシュボードを作ってみましょう。
銀行の明細はこのサンプルを利用します。このデータを多くの銀行に倣って ShiftJIS の CSV として扱います。
前提として、Google Cloud のプロジェクトが必要になるので用意してください。
以下ではプロジェクト ID が GCP_PROJECT 環境変数にあるものとして説明します。
また、Go 環境とGoogle Cloud SDKはセットアップ済みとします。
作成するリソースはそれぞれ次の名前を使用します。
- Service Account:
bqloader - BigQuery Dataset:
bqloader_dataset - BigQuery Table:
main_bank - Cloud Storage Bucket:
gs://$GCP_PROJECT-source - Cloud Functions:
bqloader-func
今回ダッシュボードには無料で簡単に使える Data Studio を使います。
Service Account 作成
Cloud Functions 用の Service Account を作ります。
gcloud iam service-accounts create bqloader --project $GCP_PROJECT
後で何回か使うので、Service Account の環境変数も設定しておきます。
SERVICE_ACCOUNT=bqloader@$GCP_PROJECT.iam.gserviceaccount.com
BigQuery の Job を実行する権限が必要になるので roles/bigquery.jobUser Role を付与します。
gcloud projects add-iam-policy-binding $GCP_PROJECT \
--member serviceAccount:$SERVICE_ACCOUNT \
--role roles/bigquery.jobUser
BigQuery Table 作成
スキーマの JSON を作成します。
cat <<EOF >schema.json
[
{
"name": "date",
"type": "DATE",
"mode": "REQUIRED"
},
{
"name": "description",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "withdrawal_amount",
"type": "NUMERIC",
"mode": "NULLABLE"
},
{
"name": "deposit_amount",
"type": "NUMERIC",
"mode": "NULLABLE"
},
{
"name": "balance",
"type": "NUMERIC",
"mode": "REQUIRED"
}
]
EOF
BigQuery の Dataset と Table を作成します。
# Dataset作成
bq --location us-east1 mk --dataset $GCP_PROJECT:bqloader_dataset
# Table作成
bq mk --table $GCP_PROJECT:bqloader_dataset.main_bank schema.json
先程作った Service Account に書き込み権限を付与します。5
bq add-iam-policy-binding \
--member serviceAccount:$SERVICE_ACCOUNT \
--role roles/bigquery.dataEditor \
$GCP_PROJECT:bqloader_dataset.main_bank
Cloud Storage Bucket 作成
生データを保存する Bucket を作成します。 Cloud Functions のトリガーとなるイベントを発行するソースにもなります。
gsutil mb -p $GCP_PROJECT -l US-EAST1 gs://$GCP_PROJECT-source
Service Account に読み込み権限を付与します。
gsutil iam ch \
serviceAccount:${SERVICE_ACCOUNT}:roles/storage.objectViewer \
gs://$GCP_PROJECT-source
Cloud Functions 実装
まずは Handler を実装します。 今回は 1 つですが、Handler が増えたときにメンテしやすいように Handler ごとにファイルをわけておきます。
// main_bank_handler.go
package myfunc
import (
"context"
"fmt"
"os"
"regexp"
"strings"
"time"
"golang.org/x/text/encoding/japanese"
"go.nownabe.dev/bqloader"
)
func cleanNumber(n string) string {
n = strings.ReplaceAll(n, "¥", "")
n = strings.ReplaceAll(n, ",", "")
return n
}
func mainBankHandler() *bqloader.Handler {
projector := func(_ context.Context, r []string) ([]string, error) {
t, err := time.Parse("2006年01月02日", r[0])
if err != nil {
return nil, fmt.Errorf("time.Parse error: %v", err)
}
r[0] = t.Format("2006-01-02")
r[2] = cleanNumber(r[2])
r[3] = cleanNumber(r[3])
r[4] = cleanNumber(r[4])
return r, nil
}
return &bqloader.Handler{
Name: "main_bank",
Pattern: regexp.MustCompile("^main_bank/"),
Encoding: japanese.ShiftJIS,
Parser: bqloader.CSVParser(),
Projector: projector,
SkipLeadingRows: 1,
Project: os.Getenv("GCP_PROJECT"),
Dataset: "bqloader_dataset",
Table: "main_bank",
}
}
エントリーポイントとなる関数を実装します。
// func.go
package myfunc
import (
"context"
"go.nownabe.dev/bqloader"
)
var loader bqloader.BQLoader
func init() {
loader, _ = bqloader.New()
loader.MustAddHandler(context.Background(), mainBankHandler())
}
func MyFunc(ctx context.Context, e bqloader.Event) error {
return loader.Handle(ctx, e)
}
Cloud Functions は Go Modules を理解してくれるので go.mod を作ります。
go mod init
go mod tidy
Function デプロイ
必要な API を有効化します。
gcloud services enable \
--project $GCP_PROJECT \
cloudfunctions.googleapis.com \
cloudbuild.googleapis.com
デプロイします。
gcloud functions deploy bqloader-func \
--project $GCP_PROJECT \
--region us-east1 \
--runtime go113 \
--trigger-resource $GCP_PROJECT-source \
--trigger-event google.storage.object.finalize \
--entry-point MyFunc \
--service-account $SERVICE_ACCOUNT \
--set-env-vars "GCP_PROJECT=$GCP_PROJECT"
CSV アップロード
CSV ファイルをアップロードして、Cloud Functions にデプロイした bqloader を起動します。
curl https://blog.nownabe.com/files/2020/12/13/sample.csv \
| gsutil cp - gs://$GCP_PROJECT-source/main_bank/sample.csv
BigQuery 確認
うまくいけば、ShiftJIS の銀行明細 CSV がいい感じに変換されて BigQuery にロードされています。 bq コマンドで確認します。
bq --project_id $GCP_PROJECT \
query --nouse_legacy_sql \
"SELECT * FROM $GCP_PROJECT.bqloader_dataset.main_bank LIMIT 5"
ダッシュボード作成
最後にData Studio6でダッシュボードを作成します。 が、Data Studio は操作が GUI で説明がめんどくさいのでフィーリングでやってみてください。 画面をポチポチやっていけば、なんとなく BigQuery の銀行明細データを読み込んでグラフが作れそうな雰囲気は感じてもらえると思います。
適当ですがこんな感じのダッシュボードを作れます。
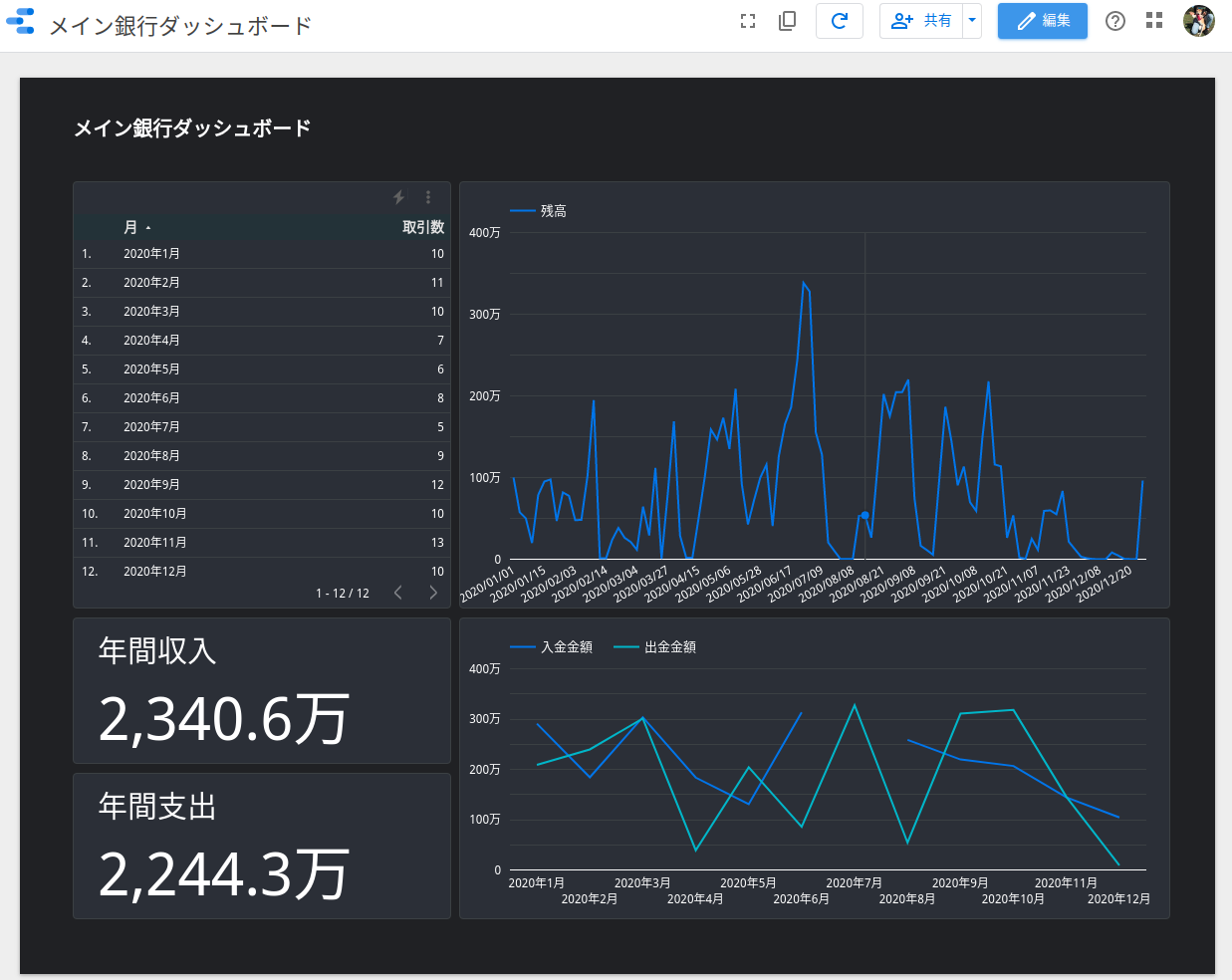
おわりに
やってみると意外と簡単で楽しいのでぜひやってみてください。 弊家では今後もどんどんデータを増やして Data Driven な家庭を目指していきます。
あ、nownabe/go-bqloader に Star くれると嬉しいです!⭐