はじめに
最近、念願のつよつよ GPU がついた PC を新調して WSL で環境構築を頑張っている。今回は GPU を使った LLM の推論を試した。
ここでの GPU は NVIDIA のもので、GPU の環境構築は WSL で CUDA を使えるようにすることを意味する。また、WSL の Distribution は Ubuntu-22.04。
LLM としては rinna 社の日本語特化 InstructGPT を使った。
GPU on WSL
基本的に この手順 に従って進めれば WSL で GPU が使えるようになる。具体的には、Windows 11 へ WSL 対応 NVIDIA ドライバのインストール、WSL 内で CUDA Toolkit インストールの 2 点。
NVIDIA ドライバのインストールは NVIDIA のドライバダウンロードサイトで Windows 11 のものを選んでダウンロードしてインストールする。最新のものであれば WSL 2 の CUDA サポートが入っている。自分の環境だとこんな感じ。
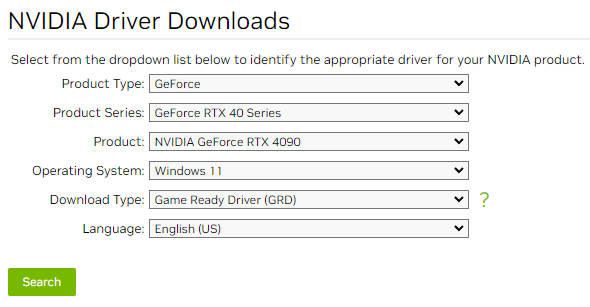
Windows 側でドライバをインストールすると、WSL 側でマウントしている /usr/lib/wsl/lib に CUDA の共有ライブラリなどが見えるようになる。
CUDA Toolkit は ダウンロードページから WSL 用のものをインストールする。これは、Windows 側でインストールした NVIDIA ドライバが提供するファイルを上書きしないように配慮されている。自分の環境だとこんな感じ。
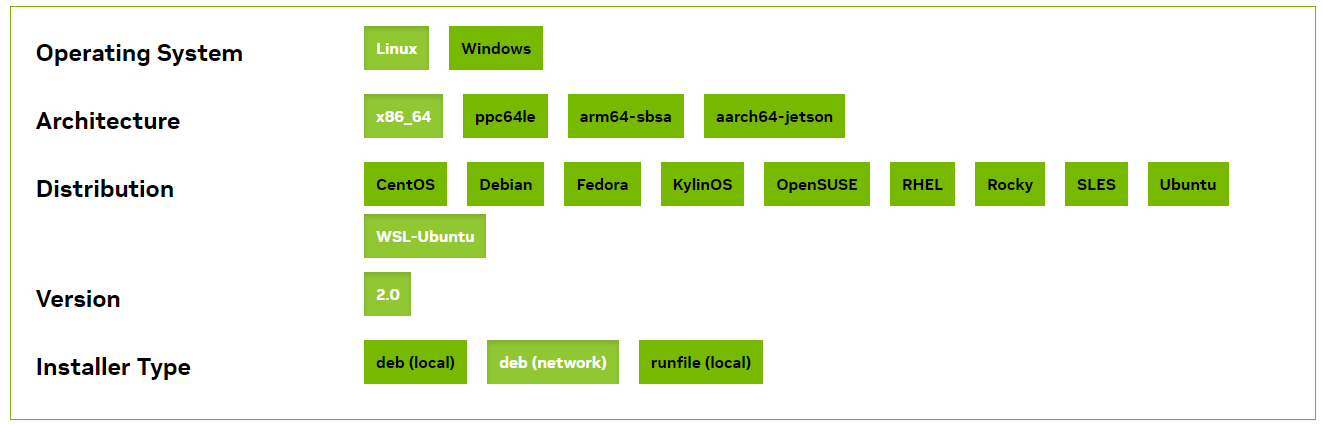
ただし、表示されたコマンドのまま進めると PyTorch が対応していない最新の CUDA (今だと CUDA 12.2) がインストールされてしまうので、こんな感じで対応しているバージョンをインストールする。
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-11-8
nvidia-smi コマンドも使えるようになっているはずなので確認ができる。
❯ nvidia-smi
Sun Jun 25 12:15:35 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.04 Driver Version: 536.23 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 On | Off |
| 0% 45C P8 39W / 450W | 1184MiB / 24564MiB | 5% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
InstructGPT
今回コンテナは使わず Poetry の仮想環境で JupyterLab を起動して、Windows のブラウザからアクセスして rinna InstructGPT を使用した。
Poetry のインストールは asdf で。
asdf install poetry 1.5.1
asdf global poetry 1.5.1
適当にディレクトリを作って poetry init。
mkdir ~/jupyter
cd ~/jupyter
poetry init
pyproject.toml の dependencies はこんな感じ。url の cp310 は Python のバージョン。
[tool.poetry.dependencies]
python = "^3.10"
jupyterlab = "^4.0.2"
torch = {url = "https://download.pytorch.org/whl/cu118/torch-2.0.1%2Bcu118-cp310-cp310-linux_x86_64.whl"}
transformers = "^4.30.2"
sentencepiece = "^0.1.99"
依存ライブラリをインストールして起動する。
poetry install
poetry run jupyter lab
Windows 側のブラウザから http://localhost:8888/ にアクセスする。トークンは JupyterLab を起動したコンソールにログとして表示されている。
まずはサンプルをそのまま動かしてみた。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-ppo", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-ppo")
model = model.to("cuda")
prompt = [
{
"speaker": "ユーザー",
"text": "コンタクトレンズを慣れるにはどうすればよいですか?"
},
{
"speaker": "システム",
"text": "これについて具体的に説明していただけますか?何が難しいのでしょうか?"
},
{
"speaker": "ユーザー",
"text": "目が痛いのです。"
},
{
"speaker": "システム",
"text": "分かりました、コンタクトレンズをつけると目がかゆくなるということですね。思った以上にレンズを外す必要があるでしょうか?"
},
{
"speaker": "ユーザー",
"text": "いえ、レンズは外しませんが、目が赤くなるんです。"
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in prompt
]
prompt = "<NL>".join(prompt)
prompt = (
prompt
+ "<NL>"
+ "システム: "
)
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
repetition_penalty=1.1,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)
ちゃんした日本語が出力される。
わかりました。コンタクトレンズを長時間つけっぱなしにしている場合は、目の周りに水ぶくれができやすくなります。また、コンタクトレンズを長時間つけたままにしておくことで、目にゴミやほこりが入りやすくなり、それらが刺激となってかゆみを引き起こすことがあります。そのため、コンタクトレンズを付ける前には必ず手を洗って、清潔な状態にすることが大切です。</s>
こんな関数を作っていろいろ遊んでみた。
def chat(prompt):
prompt = f"ユーザー: {prompt}<NL>システム: "
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
repetition_penalty=1.1,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
return output.replace("<NL>", "\n")
Windows 11のWSL2でRTX4090使ってLLM動かせた! pic.twitter.com/FsbVMZ0toe
— ぎっくり腰太郎 (@nownabe) June 24, 2023
メタルはあんま詳しくなさそう https://t.co/GTLceXCPek pic.twitter.com/PtkBdkLXUB
— ぎっくり腰太郎 (@nownabe) June 24, 2023
推論してるときのリソースはこんな感じ。
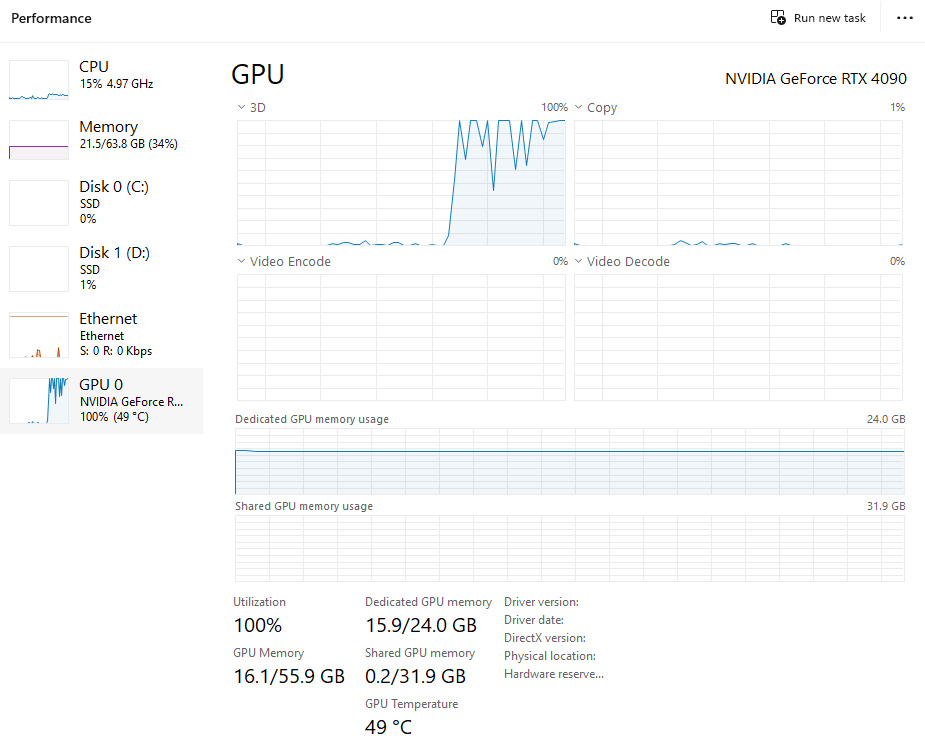
おわりに
ローカルで LLM 動くの楽しい!